Predictive maintenance is rapidly gaining momentum as a game-changer for businesses reliant on physical assets. With the aid of data analysis, statistical algorithms, and Machine Learning (ML) methods, we can now predict when equipment will require maintenance, enabling us to act before costly breakdowns occur. As we gather more data, these techniques offer us the opportunity to enhance both capital and operational efficiency.
Empowering Asset Reliability through Artificial Intelligence
Imagine a world where you can foresee the future, especially when it comes to the well-being of your critical assets. Welcome to the exciting realm of predictive maintenance, where the power of data and cutting-edge techniques converge to revolutionize asset management.
Predictive maintenance is rapidly gaining momentum as a game-changer for businesses reliant on physical assets. With the aid of data analysis, statistical algorithms, and Machine Learning (ML) methods, we can now predict when equipment will require maintenance, enabling us to act before costly breakdowns occur. As we gather more data, these techniques offer us the opportunity to enhance both capital and operational efficiency.
We split predictive maintenance into two types: understanding gradual decay to better anticipate and plan maintenance (see for example this project), and predicting acute breakdowns in order to prevent or prepare for them. This article focuses on the latter as we see a lot of untapped potential.
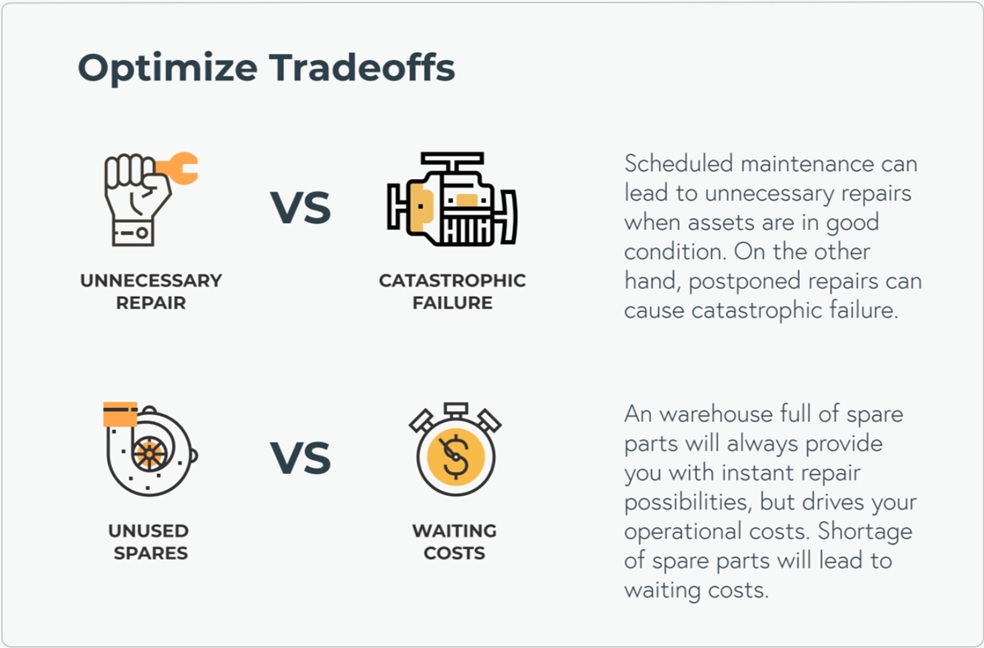
Acute breakdowns can lead to unscheduled downtime, higher-cost maintenance, and potentially even unsafe situations. This means it can be very valuable to leverage algorithms trained on patterns of historical data to predict and prevent these breakdowns. Many organizations are not aware of this value however, and they accept unnecessary downtime and costs as a result; they simply have not yet entered the age of big data when it comes to failure prevention.
The end-to-end process to prevent breakdowns consists of several elements. First of all, data such as sensor readings, operating conditions, and performance metrics need to be collected and stored. Then this data is fed into a failure prediction model, and finally action should be taken based on these predictions. We first focus on the failure prediction models, and next discuss how to implement these tools in the organization so it actually leads to preventative action.
Methods for predicting failures
For several types of assets, breakdowns occur often enough that sufficient historical data is available to train artificial intelligence (AI) models to recognize the conditions that preceded failures in the past. We have used techniques like Survival Analysis, which predicts what percentage of components would fail within X years. This model can be very powerful, but requires tweaking and additional care when applied to assets with non-monotonic failure rate. Also other AI models can also be used, such as Random Forests, Neural Networks and Time Series models. Which model performs depends on the circumstance such as the amount and type of (un)structured data, but in practice is often a result of trial and error: which one performs best to predict past failures.
One clear benefit of this approach is that these predictive models can continually refine themselves based on new data, and become increasingly proficient at identifying early signals of impending failures. It is also possible to analyze which data sources are most important to the model, suggesting potential data gathering improvements that can further improve the early-warning of upcoming failures. This is especially relevant for critical assets that have a significant impact when breaking down.
Using this methodology, we could for example predict the failure of certain types of railroad switches. The algorithm we used recognized the pattern of power consumption when the switch was activated to change tracks. This pattern proved indicative of an upcoming failure within the next 2 weeks. Of the investigated switches, around 40% of breakdowns could be predicted, providing a potential cost saving of €3M per year, even excluding the significant societal benefits of reducing train delays. See for example our innovation nomination that touches on this topic (in Dutch).
But we also regularly encounter situations where breakdowns do not occur frequently enough to train algorithms on past failures. In that case condition monitoring with anomaly detection can be a good solution. With condition monitoring, the state and performance of equipment and infrastructure is continuously assessed. Anomaly detection can then identify patterns that sufficiently deviate from the norm to conclude or at least hypothesize that something is off, warranting (manual) inspection.
Anomaly detection can be implemented with different Machine Learning / AI techniques, which should be carefully tailored to the specific situation to ensure the best performance: optimally recognizing true outliers without generating too many false positives (‘crying wolf’). Some examples of these techniques are isolation forests, where anomalies are detected by measuring how quickly data points are isolated in decision trees. Another method is using so-called autoencoders where an artificial neural network is trained to predict for example the next measurements in a time series. When an anomaly occurs, it is sufficiently different from the expected measurement that it can be detected.

Implementing failure prediction and prevention
Putting failure prevention in practice, should start with a high-level understanding which assets are key. We also often recommend starting small, with a relatively simple use-case for which sufficient data is available, in order to experience its value and create traction within the organization for the approach. This is also why it is important to early on involve the people (maintenance engineers, planners, etc) involved in actually executing the recommendations.
The next step is to ensure the data intake. Next to (near) real-time information on the state and performance of the asset, it can also be very helpful to have sufficiently good meta-data. This can include its physical context, installation date, and its version, and therefore which components are used. We supported for example one of our energy clients with better structuring and improving the accuracy of district heating master data. These additional inputs can be very powerful in distinguishing likely situations where a breakdown can occur.
Next, the actual prediction algorithms mentioned above should be trained, refined and tested.
When the likelihood of failure is sufficiently high, the question becomes whether, when, and how to intervene. This depends on multiple factors. One perhaps surprising element to take into account, is the additional risk that intervening itself creates; for some types of equipment, we see that recent maintenance or inspection activity itself is significantly increasing the likelihood of failure, even if no previous indication of failure was present. Next to this, of course cost considerations are important, but also the impact of the failure on overall operations. For this, we see increasingly digital twins and other simulation tools being used.
Finally, the recommendation should be fed to the maintenance engineers involved in the interventions. This can be using a dedicated dashboard, a warning system, or ideally embedded in existing digital planning tools. Again, involving these users early-on in the process is a crucial factor for success.
These steps should typically be done iteratively to most efficiently work towards a solution.
Want to learn more?
If you’re eager to explore failure prediction and prevention or other ways to harness data for your company’s digital transformation, don’t hesitate to reach out to Melvin Meijer.
The future of asset reliability awaits, and it’s driven by the power of data and AI.




